Case Media
Case Notes
This page keeps the media, full prompt, and original source together so you can inspect the result first and decide whether the prompt is worth copying, saving, or comparing.
Case Insights
To make this page easier to search, cite, and reuse later, the case is also broken down into practical guidance about usage, visual cues, and prompt structure.
Best Fit Scenarios
- Use this as a poster & illustration benchmark when you need a fast style baseline before rewriting your own prompt.
- It is especially helpful if your target overlaps with Poster, Illustration, Infographic and you want to judge the image result before tuning wording.
- Keep it as a control sample when you compare nearby prompt variants one variable at a time.
Visual Signals To Notice
- The clearest style signals here are Poster, Illustration, Infographic, so those should usually stay in your first rewrite.
- Pay close attention to layout rhythm, headline hierarchy, illustration texture, and how information is staged in the frame.
- This case keeps one primary output, so the first image should be treated as the main visual reference.
How The Prompt Is Structured
- The prompt reads as a long, highly specified prompt, which is useful when you want to judge how much specificity this direction needs.
- Its keyword cluster is centered on Poster, Illustration, Infographic, so you can usually keep that cluster while swapping subject, camera, layout, or copy details.
- A practical rewrite path is: keep the outcome, keep the strongest style cues, then replace only the subject and environment blocks.
Good Follow-up Questions
- What changes first if you keep Poster, Illustration, Infographic but switch the subject matter?
- Which part of the result comes from section-level structure (Poster & Illustration) versus tag-level style cues?
- Which related cases in the same section give you a cleaner or more extreme variation of the same direction?
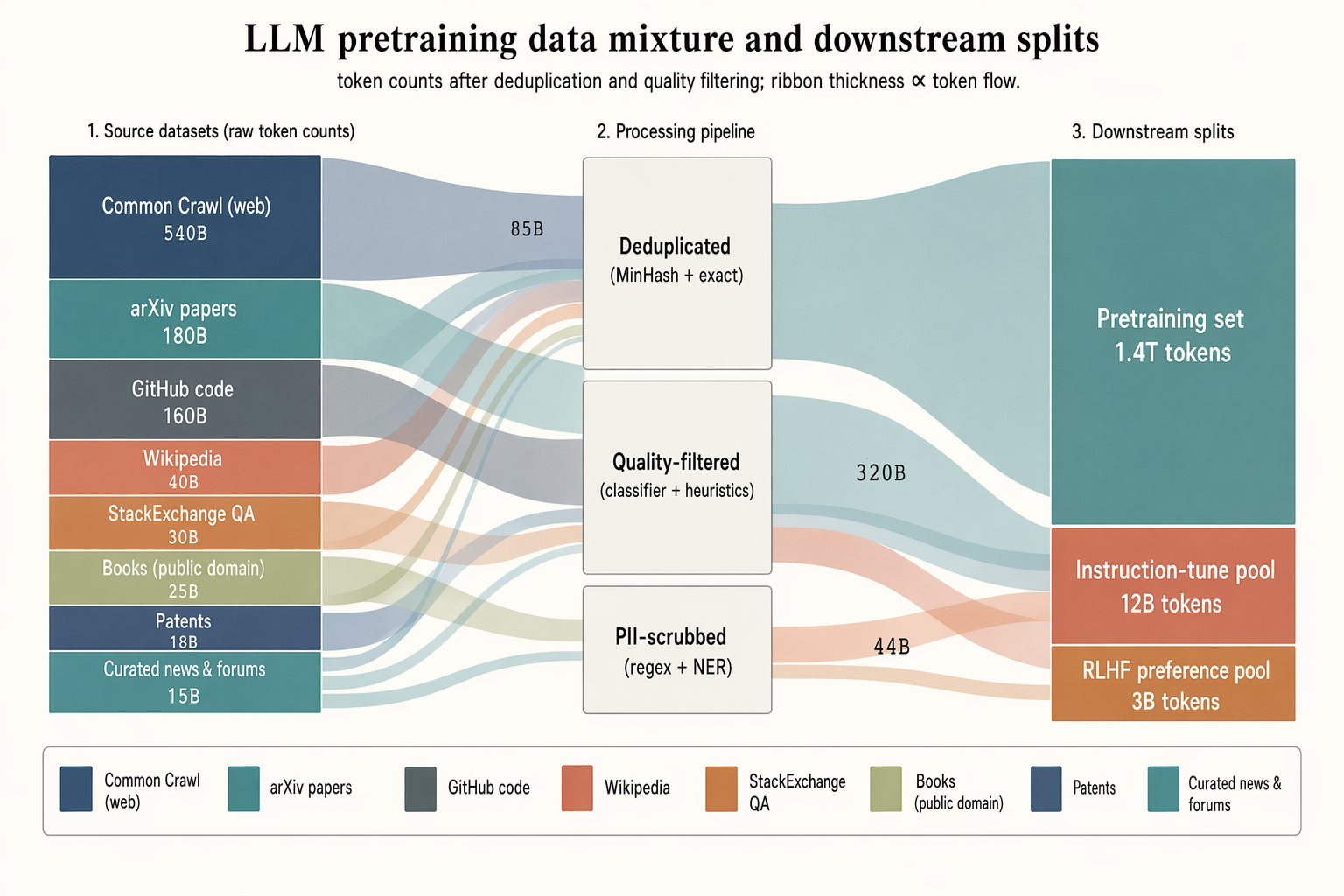
Full Prompt
Landscape 16:9 sankey diagram of a pretraining data mixture, three stages with translucent colored ribbons. LEFT (8 source blocks, heights proportional to tokens): "Common Crawl (web) 540B" (muted navy, largest), "arXiv papers 180B" (dusty teal), "GitHub code 160B" (slate gray), "Wikipedia 40B" (soft terracotta), "StackExchange QA 30B" (warm copper), "Books (public domain) 25B" (pale olive), "Patents 18B" (pale navy), "Curated news & forums 15B" (dusty teal). MIDDLE (3 processing blocks, stacked): "Deduplicated (MinHash + exact)", "Quality-filtered (classifier + heuristics)", "PII-scrubbed (regex + NER)". RIGHT (3 final splits): "Pretraining set 1.4T tokens" (largest), "Instruction-tune pool 12B tokens", "RLHF preference pool 3B tokens". Flow ribbons inherit source color with mid-labels showing token counts ("85B", "320B", "44B"). Legend strip at bottom. Title: "LLM pretraining data mixture and downstream splits". Subtitle: "token counts after deduplication and quality filtering; ribbon thickness ∝ token flow."



